
What I take from the concept of Web 3.0 is the idea of making machines smarter, more 'intuitive'. Of course, since computers are inherently stupid, this involves us giving the means with which to become smarter and more intuitive. Like giving them the semantics to work with, in order to retrieve data more effectively. In short, data is not only machine readable, but machine understandable.
This is all technically theory, since the semantic web doesn't really exist - yet. We still don't really have a system whereby computers can build programmes, websites, mashups, what have you, in an intelligent and 'intuitive' way according to our needs. But the potential is there, with tools like XML and RDF. These involve the creation of RDF triples, taxonomies, and ontologies. What the hell, you may ask? And I may well agree with you. How I've come to understand it is that these are essentially metadata applied to information in order to relate those pieces of information together in a semantic way. These relationships between data or pieces of information make it easier to retrieve them, because they are now given a context within a larger whole.
This does have its parallels with Web 1.0. RDF Schemas (taxonomies expressed as groups of RDF triples) have a certain similarity to the concept of relational databases. RDF schema 'nodes' can be equated to the primary key in relational databases. In fact, the whole idea of RDF schemas can get a little confusing, so some of us found it easier to think of it in terms of a web-based relational database.
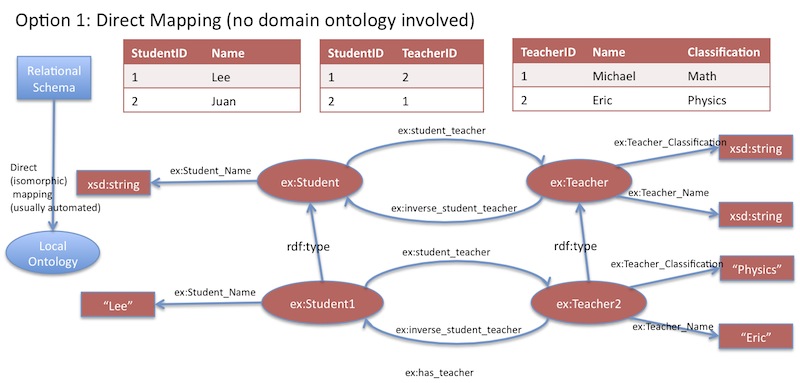 |
| Relational database <-> RDF schema |
The potential to make even more advanced and relevant mashups is the huge advantage of this technology. However, the problem is that it requires quite a bit of skill and time investment in order to create these schemas, taxonomies and ontologies. Most people would be satisfied with what they can create via Web 2.0 technologies - with social networking, blogging and mashups. The potential to make faulty schemas is also a problem - as with a database, any error in organising the information, or in the data retrieval process will mean a complete inability to access data.
But the main problem I see is that these schemas are only really applicable to certain domains, such as librarianship, archiving, biomedics, statistics, and other similar fields. For the regular web user, there are no particular benefits to applying an RDF schema to, say, your Facebook page - but it would probably be useful to Mark Zuckerberg.
The semantic web is probably more useful in the organisation of information on the web, and harnessing it. But it would probably be largely invisible and irrelevant to the legions of casual web users out there.
